| |
Mangling Data with Spreadsheets |
|
This page is devoted to the science of "mangling" one-name data with a spreadsheet program. Very large tables of data can easily be reformated using the standard "functions" available in most spreadsheet programs. The following methods have been tested in either a German version of Microsoft Works 4.0 or an English version of Word Perfect 6.1 but should be easy to adapt to any other spreadsheet software, particularly Microsoft Excel.
The following examples all assume that data has been placed in row 2 of the column marked A, with any supplementary data in columns B and C. The functions should be placed at the top (row 1) of an empty column and can then be copied all the way down it using the data-fill function. The IF/WENN function ensures that if one cell in the column is empty, no error message will appear, but the data fill will simply skip the relevant cell.
You will probably not be able to cut and paste these functions into your spreadsheet, because it will read the semi-colon as a tabulation character and split the functions over several columns. Print out the list and copy the functions by hand when you need them so that you understand them better. I have also included my MS Works spreadsheet file, which functions in a German version of Windows 98: whether it functions in other versions is unknown: you are welcome to try it, but I offer no assurances.
This formula simply eliminates double or triple letterspaces between words. These usually come into copy from careless keying, e.g. words with gaps, or when fixed-width fonts have been justified.
English: =IF(A2<>"",TRIM(A2),"")
German: =WENN(A2<>"";GLÄTTEN(A2);"")
This is handy for reducing text written entirely in capital letters to a more legible upper and lower case format, e.g. TOM BROWN to Tom Brown.
English: =IF(A2<>"",PROPER(A2),"")
German: =WENN(A2<>"";GROSS2(A2);"")
Gordon Adshead points out that several columns can be converted at once in Excel by opening up a second worksheet, and using Fill Down and Fill Right to copy every cell starting from
=proper(Sheet1!A1)
This converts text with the format 12/09/2000 to the ISO standard 2000/09/12. The latter has the advantage of sorting correctly while only needing a single column to display.
=WENN(A2<>"";TEIL(A2;6;4)&"/"&TEIL(A2;3;2)&"/"&TEIL(A2;0;2);"")
This is the reverse of the above operation, converting ISO dates into the format DD/MM/YYYY which is usual in the Commonwealth countries.
=WENN(A2<>"";TEIL(A2;8;2)&"/"&TEIL(A2;5;2)&"/"&TEIL(A2;0;4);"")
Combine the text in column A (e.g. Tom) with that in column B (e.g. Brown) so that the new column contains "Tom Brown": the "if" condition has to be further modified in this example to ensure that lines with no text in them at all are ignored, but lines with only one column filled show up as errors. You can then inspect these errors to see if they indicate defective data, or you might wish to write in by hand that data is missing, e.g. "--- Brown".
=WENN(ODER(A2<>"";B2<>"");A2&" "&B2;"")
This is particularly useful to create identification numbers along the lines of G3001, G3002, R0004 and so on. Fill column A with the chosen letter or word on every line (use the data fill function) and create the number sequence in column B (use the data fill sequencer). They can then be combined. Note that an AND condition has been used here instead of an OR: you do not need any errors to be flagged and so there will be no product at all unless both columns A and B contain entries.
=WENN(UND(A2<>"";B2<>"");A2&(ZEICHENFOLGE(B2;0));"")
This example demonstrates a way of combining text from three columns in such a way that only column A is a required one: sort your spreadsheet first so that all the entries with A entries in them are at the top. Then run the formula in a blank column, D for example. You will find that if C is empty the formula still yields AB. If B and C are empty, it produces just A as the result. For example suppose your columns read Year - Month - Day, then the results could be 1945, 1945 Oct or 1945 Oct 26 depending on how precise the available information was. No error messages are given. Using this formula assumes your table has already been highly refined.
=WENN(A2<>"";(A2&" "&(WENN(B2<>"";B2;""))&"
"&(WENN(C2<>"";(WENN(LINKS(C2;1)=" ";"0"&RECHTS(C2;1);C2));"")));"")
Several of the above examples assume that years or days are being formatted as text, not as numbers. However you will find that MS Works and Excel will not allow you to reformat a number as text using the "Format" menu. Here is a formula that lets you create a whole block of "text-formatted" numbers. You can then cut and paste them (using Paste Special) on top of the original badly formatted numbers. But make sure you make a back-up of your file in case this operation goes wrong.
English: =TEXT(A2,0)
German: =ZEICHENFOLGE(A2;0)
When you receive documents with Windows-format dates (between 1900 and 2079), you may want to format these into ISO text dates to make them compatible with other (older) dates in your table. Here is a simple formula to do so (and you can be quite sure it will be formatted as text because of the presence of the "/" or "." signs):
English: =YEAR(A2)&"."&MONTH(A2)&"."&DAY(A2)
German: =JAHR(A2)&"/"&MONAT(A2)&"/"&TAG(A2)
Spreadsheets are excellent at lopping off parts of words. For example if you only want the first seven characters of all the words from column A, use this formula:
English: =LEFT(A2, 7)
German: =LINKS(A2; 7)
However what do you do if you want all the (unknown number of) characters except the first seven? Try using a "right" formula that first counts the entire number of characters, then subtracts seven:
English: =RIGHT(A2,LENGTH(A2)-7)
German: =RECHTS(A2;LÄNGE(A2)-7)
You can also write a formula that finds a set number of characters near a unique character. In the following case, the result (e.g. 5830,93 returns the result 830) is then reformatted as a number.
=WERT(TEIL(A2;(FINDEN(",";A2;1)-3);3))
Here is a formula that can take a phone book name, e.g. Brown, Tom, and turn it around - surname last, no comma, i.e. Tom Brown. You will see it works as follows: it parses the name until it finds the first letterspace and then takes the entirety of the entry after that (giving the somewhat larger full length as the term will satisfy most spreadsheets) as the first part of the result. It adds a space. It then looks for that space a second time and takes the entry to the left of that to be the surname. This function can easily be modified to separate surname and first name into separate fields, which represents better database practice.
=WENN(A2<>"";TEIL(A2;(FINDEN(" ";A2;0)+1);(LÄNGE(A2)))&"
"&LINKS(A2;(FINDEN(" ";A2;0)-1));"")
Turning Firstname-Surname strings into Surname-Firstname is a bigger challenge, because, with multiple middle names, there may be several spaces before one reaches the surname. When spreadsheets parse, they start at the left, whereas what we need is a function that seeks the first space starting from the right. Sophisticated scripting languages using "regular expressions", like PERL, can do this. Spreadsheets cannot.
Keith Fryer of London has kindly suggested a useful approach that makes the problem manageable: splitting the text word-by-word across columns.
"I've used this method before, and whilst it's not infallible, it does work well enough that the few situations where it doesn't aren't too much of a problem. I used text-to-columns rather than complex formulae, but you could use your split-by-word formula as a basis," he says.
1. Split the name data by the space character (" ") using text-to-columns. This will give you an unspecified number of columns, so it is best to start with a single column in a blank sheet. You can then delete the original column.
2. You might need to add conditions to this formula depending on how many names people in your directory have - this accounts for surname+4 forenames, so unless people are being greedy it should suffice - but you can always add more (up to whatever the nested statement limit is).
=IF(E2="",IF(D2="",IF(C2="",B2 & ", " & A2,C2 & ", " & A2 & " " & B2),D2 & ", " & A2 & " " & B2 & " " & C2),E2 & ", " & A2 & " " & B2 & " " & C2 & " " & D2)
"It seems to do the job. This works in Excel 2002. One place it can fall down is if your list has qualifications in it - Tom Brown, MD, PhD would become PhD, Tom Brown MD!" Keith notes.
I tried a variation on this: splitting names into a first-names and a surname column. I started by using search-and-replace in a word processor to convert any double spaces to single spaces (method 1 above would also have worked), then substituted for each space the ˆt symbol that Microsoft programs used to denote a tabulation mark. Then I cut-and-paste the entire text to MS Works Spreadsheet: the text was automatically split across columns wherever the tabulation mark appeared. The body of information spread itself across columns A to E and remained highlighted, so I immediately knew that while some names only filled two columns, the longest names filled five.
I then prepared column F to receive the first names using the following formula:
=WENN(E2="";WENN(D2="";WENN(C2="";A2;A2&" "&B2);A2&" "&B2&" "&C2);A2&" "&B2&" "&C2&" "&D2)
while the surname column (G) was filled using this formula:
=WENN(E2="";WENN(D2="";WENN(C2="";B2;C2);D2);E2)
It worked a treat with 3,000 names. Thanks very much, Keith!
If none of this works for you, you may have to contemplate the steeper learning curve of "regular expressions", a set of software routines that has been available for many years to process text in ingenious ways. Regular expressions can not only process text even before it has been tabulated and separated into digits and letters, but can also be used to discover recurrent patterns in text.
Scripting languages such as Perl and JavaScript come with regular expressions included, but the easiest way to put them to work is to use text editing software that offers them as an option. DreamWeaver comes with search-and-replace routines that have regular expressions built in, but it is extremely expensive. I recommend you grab a copy of the freeware text editor NoteTab Light, which does the job just as well. Open the search-and-replace box and this is what you will see:
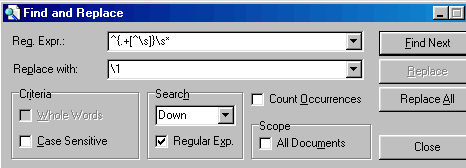
You write the form of text you want to alter in the top box. In the bottom box you describe what text you wish to retain, and how it should be modified. Don't forget to tick the box "Regular Exp." before starting.
A point < . > is the code for any character other than "new line" (the two characters carriage return and line feed). If you enter (.)+ the software will look for one or more such characters.
It is possible to look for a range of selected letters or numbers by keying them in like this: <a-z> or <0-9>. The latter means the same as (0123456789). A dollar sign <$> has the meaning "at the end of a line", so you could for example search for numbers at ends of lines with this code: [0-9]$.
Curly braces, <{> and <}>, are used to mark the text that you want to retain in the replacement. You can retain up to nine chunks of text on every pass. The syntax looks this: <backslash1-9>, so \1 would mean the first chunk of material from the left enclosed in curly brackets in the upper NoteTab box.
This is merely to give a foretaste of how regular expressions work. The Help file that comes with NoteTab Light explores in more detail how to use these techniques, and explains the example in the screenshot above. The book Regular Expressions by Jeffrey E. F. Friedl, published by O'Reilly, is the "bible" on the whole subject and contains all sorts of ingenious solutions to text-mangling problems.
You can download NoteTab Light from the website www.notetab.com where there are also links to forums with more information.
© Jean-Baptiste Piggin 2000-2009

This page is licensed under a Creative
Commons Attribution-No Derivative Works 3.0 Unported License.